Last Updated: November, 2023
What Is Intelligence?
As we asked in the previous section, what even is intelligence? In the interest of defining terms, it'd be a good idea to start with that one. In lieu of a precise answer that both pleases everyone, and is specific enough to be useful, I'll begin by describing how intelligence comes about in humans, and we'll see where we go from there - Nature versus Nurture is a good concept to keep in mind for this.
Humans are pattern recognition machines, the most sophisticated pattern recognition machines we've ever encountered/created. Hence, you could begin by saying that intelligence is simply a measure of how quickly a human can recognise a pattern, how complex a pattern a human can recognise, how disparate/abstract the pattern being recognised is, and most importantly, how accurate the recognised pattern is - these are all various metrics for evaluating pattern recognition ability.
That said, what's the use of having extremely advanced pattern recognition abilities with zero experience/memory to train that pattern recognition on? How could a sophisticated pattern recognition machine be, or do anything, of use, with zero context or data? Hence, intelligence is then an emergent ability that only manifests itself through experience/memory, specifically analysis of experience/memory, be that analysis conscious or (more often than not, I'd say) unconscious. You can't show intelligence without producing something that you can pour your intelligence/reasoning into, which is inherently to experience. You can't actually see a strong breeze, but you can see how a strong breeze blows things around; we point at the wind blowing through tree leaves and say "look, that's the wind". It seems, then, that "intelligence" is a marriage between experience/memory and analytical ability; it is only from in-depth analysis (conscious or unconscious) across our accumulated experience in life that our intelligence emerges. Those of you playing along at home that are already familiar with how AIs and LLMs are created can probably see where I'm going with this.
Two Metrics
With an LLM, you could say there are two metrics that combine to form its intelligence; the quality and quantity of its training dataset, and the efficacy and quality of the training method/model. Optimising the creation, combination, and integration of these two areas is the primary goal of anyone creating an LLM. Obviously, this is still extremely high-level, and not really useful in terms of insights into LLM creation, but I find the degree of overlap between describing the emergence of human intelligence and artificial intelligence extremely fascinating. What's more fascinating, however, is looking at the differences.
I think another pitfall towards understanding these artificially intelligent LLMs is that they are not of a human kind of intelligence. I think a lot of people struggle to understand non-human types of intelligence, and as such are quick to judge that they are not intelligent, when what they are is not of human intelligence, and (currently) very limited in the amount of intelligence that can be applied in any one go. A fantastic example of what I mean by "non-human" intelligence is in comparing an LLM's mathematics and programming abilities.
Without any tool use, LLMs notably used to struggle to evaluate from about university-level maths onwards, or maths involving very large/very long numbers - initially with little extra ability to gain from specific prompting, either. Contrast that with an LLMs ability to write code, particularly python code - they excel at this. I've found one of the biggest time-savers something like GPT4 provides is scripting in python. There is a bit of an art to prompting it to do what you need, and you still need to know python yourself to be able to identify problems when they arise, but most LLMs are fantastic at scripting with python. This seemed paradoxical to me - how could an intelligent entity be concurrently bad at mathematics but good at programming? Wouldn't an understanding of the underlying logic of mathematics be a prerequisite for understanding how to effectively write code?
Complexity and Cognition
Ask anyone if they know maths; they're likely to respond with "yes". Ask again to evaluate 5 * 2; they're likely to respond instantly with "ten". Ask again to evaluate 75 * 3 * 4; they're likely to respond with "nine hundred", albeit with a bit more of a delay. Ask one final time to evaluate 4721892876742587942 * 12351625356482377215523 * 123578425762; they're likely to question your intelligence. So, what's the problem? The individual clearly knows mathematics, why then can't they answer a simple, relatively basic maths question?
There are two types of processes that occur in the human brain; the lightning-quick, unconscious, heuristic analysis, and the (relatively much) slower, conscious, deliberate analysis - we'll call these the 'unconscious' mind, and the 'conscious' mind. A single task can, and generally does, span many different primordial domains (e.g., linguistic, kinetic, mathematic, operational, habitual, etc). Combine this with an individual's mindset and preferences, and there are many different things going on at once, some conscious, some unconscious, to varying degrees per individual per task. This is all to say; tasks exist on a per-person spectrum between conscious and unconscious, and you can somewhat estimate the percentage of each involved, ast least for argument's sake.
It is the conscious mind's job to handle unique and/or complicated problems, one of which is performing and simplifying complex pattern recognition such that it can describe and catalogue particular discrete subsections of the world around it to offload previously-complex tasks to the unconscious mind. This allows the unconscious mind to perform those tasks "in the background", freeing up attention, presence of mind, and 'intellectual energy' to be spent on other tasks. A fantastic example of this is driving - when you first get behind the wheel of a car, there is so much going on around you, so much to remember to do correctly such that it can be rather overwhelming. Contrast that to once you have at least 1000 hours of driving experience, where everything is second nature, and seems to happen autonomously. Before moving on, I'd like to mention that the notion of having two processes (conscious and unconscious) in the mind is not my own idea. This is called "Dual Process Theory", and I would recommend reading more about it.
I'd say the difference between those three maths questions is simply a difference of the ratio of where the computation is occurring within the human mind: evaluating 5 * 2 occurs overwhelmingly within the unconscious, to pull a number out of thin air, let's say '99.9% unconscious, 0.1% conscious', hence the instantaneous response. Evaluating 75 * 3 * 4 is a little bit more complicated, let's say '90% unconscious, 10% conscious", hence the slight delay in answering. The last evaluation, 4721892876742587942 * 12351625356482377215523 * 123578425762, is a lot more complicated, again let's say '2% unconscious, 98% conscious'. I've just pulled those numbers out of thin air, but they illustrate my thinking towards this, also, these numbers represent values that I would imagine the average person would agree with. I would also mention that, within this analogy, a calculator performs "conscious" evaluations - in some senses, they are hardwired to perform these tasks "consciously", hence why they are so incredibly useful for evaluating mathematics equations such as that third one.
An LLM's "computation", on the other hand and for all intents and purposes, is entirely unconscious. It is always within its own hallucinatory, dream-like train of thought, where the instructions and context we give it exist as semantic lighthouses, guiding this train of thought in the direction you want it to go. This is all to say that, the closest comparison in humans to how something like GPT4 "thinks" would be looking at only the unconscious mind. There isn't any higher-level thought (yet), but you can "trick" it into doing some higher-level thought. Its main sense is text, and each generated token is somewhat analogous to a discrete piece of "intelligence" used to solve the particular problem at hand. Solving the same problem twice, but on the second time around you get it to take it slowly and it spends 2x the tokens, you could probably say you've doubled the amount of "intelligence" used to try to solve the problem, but this is getting a bit off-topic.
Jumping back a bit; ask any scripter/programmer to describe the mental function that outputs code. I'll touch briefly on my own personal experience, but first I feel I should specify what kind of programming I'm talking about. I program in python; I create shitty little scripts to do various tasks generally involving some sort of automated analyses of structured data and API calls to distill out some specific, useful information. Object-oriented scares me; I don't work in a team, and I'm almost always the sole contributor to my repositories. When finished, I generally do my best to refactor, optimise, modularise, and comment my code. My programs are generally less than a few hundred lines, and always less than 1000 lines. When I'm writing a new script or program, I would already have some high-level unconsciously-created understanding of what my program and its various functions need to do - a schema. I then expend conscious cognitive effort to wrangle and bend python in such a way as to manifest the program as closely as possible to the schema I have of it - this is an example of expending conscious cognitive effort to fill out the lower-level parts of the program's schema. The more familiar one is with python, the more comprehensive that unconsciously-created schema is, and the further towards the lower-level it extends, hence making the work easier.
tl;dr, it only appears to be paradoxical that LLMs are simultaneously bad at mathematics but good at programming because it would be somewhat paradoxical for a human intelligence, but not an artificial intelligence. A human must learn mathematics, or how to program by consciously breaking down each step from start to finish, where patterns and shortcuts are detected and remembered, as the conscious mind slowly hands off control to the unconscious mind. An LLM, on the other hand, can simply be given truckloads of example information in which to artificially construct a unconscious mind by expending a huge amount of 'conscious' computation as an initial once-off - we call this "training". In terms of "conscious" computation, an LLM (currently) struggles greatly. Next we'll focus on how to extract usefulness out of LLMs.
Depth and Breadth
Consider a regular 2d graph.
The horizontal x-axis we label "Breadth", and the vertical y-axis we label "Depth". And lastly, we have a notable variable, a for "Ability", where a = depth * breadth. Hence, the area within whatever shape drawn on this 2d graph must be less than or equal to depth * breadth. Picking a number, we'll say that this graph extends 0 - 10 on both axes. This is what I'm calling the 'ability graph', and it's a way to convey the difficulty of a particular task, at least in the abstract.
Consider this to be a representation of where cognitive "effort" is being expended. Here is an example of specialisation and generalisation:
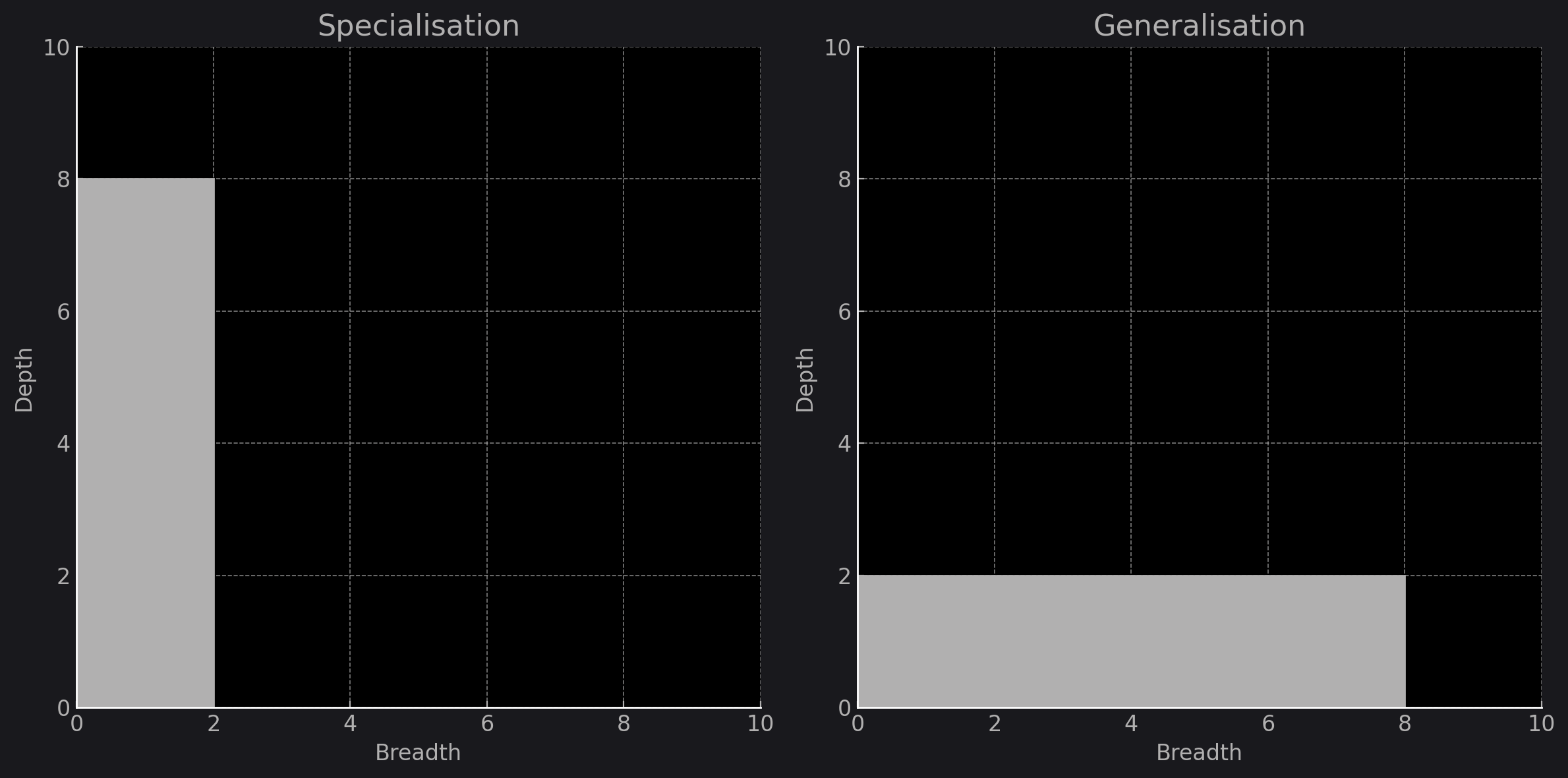
When we talk about the capabilities of an LLM, it's crucial to understand the dimensions of its intelligence. This is where the 'Depth and Breadth' model comes into play - a conceptual framework to quantify an LLM’s capacity for task execution. Think of it as the mental 'work area' where cognitive labour is performed. 'Depth' is akin to the level of expertise or specialisation an LLM has in a particular domain. It's the measure of how deeply the model can delve into a task, showcasing nuanced understanding and sophisticated, intelligent responses.
'Breadth', on the other hand, is the scope of application. It's the range of topics, scenarios, and problems that the LLM can handle. 'Breadth' is the horizon-touching, far-seeing gaze over a field, encompassing a vast array of elements. Each task we set for an LLM has a certain 'ability' threshold - a maximum 'a' value that defines the total cognitive effort the model can exert, intrinsic to the task at hand, and the model itself. A task like Python scripting may have an 'a' value of 20; linguistic analysis maybe an 'a' value of 100.
It's important to note that while an LLM may inherently possess a vast repository of data, its efficacy in a task hinges on how it utilises this information. By directing the LLM's focus - through fine-tuning and prompting - we can 'shape' its area of ability, pushing the borders of 'Depth' or expanding the frontiers of 'Breadth'. However, this 'Depth and Breadth' balance is subject to a law of conservation - the total area of 'a' remains constant, much like energy in a closed system. You can't create or destroy 'ability', only channel it. For any given task, if we increase 'Depth', 'Breadth' must proportionally decrease, and vice versa. This is the trade-off between specialisation and generalisation.
Hence, if you, the reader, can perform some of the high-level, high-breadth thought for it, rather than the LLM needing to do it itself, then (via specific prompting) you can get it to expend all of it's cognitive energy pushing depth while limiting breadth. This is how you get it to perform at its best - provide it specific context, instruction, directions and examples, and an LLM should be able to hallucinate a useful output for you. For example, here's three ways you could ask for an LLM to create you a program. Which do you think works "best"?
"Write a Python script that analyses tweets."
"Write a Python script that can determine the sentiment of tweets about a new tech product launch."
"Create a Python script using the Tweepy library to stream live tweets by searching for the hashtag '#TechProductXLaunch'. Use the TextBlob library to perform sentiment analysis on these tweets in real-time. The script should classify each tweet's sentiment as positive, negative, or neutral based on the polarity score. Compile the results into a summary report that shows the percentage of positive, negative, and neutral sentiments, and print this report to the console."
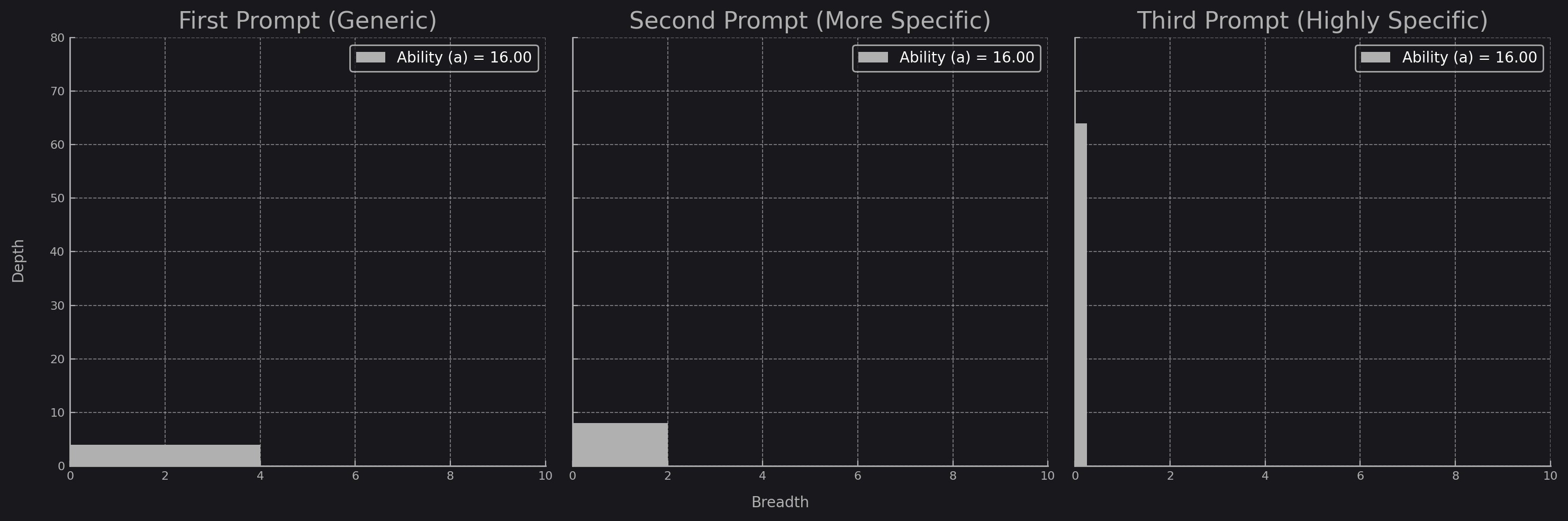
The third prompt is clearly the one with the highest efficacy, being able to immediately turn your thoughts into a well-described problem statement such as that is extremely useful. I said before it's possible to "trick [an LLM] into doing some higher-level thought", and what I meant by that is that it's viable to have a workflow consisting of multiple models chained together, each model heavily specialising in one particular thing. In this example, that could take the form of another LLM with instructions to determine exactly how to perform some general task - how to turn the second example prompt into the third example prompt. This specialised LLM determines which libraries to use, how the program should function, etc etc. Then, it passes that description off to another LLM that actually creates the program.
Conclusions
To harness the full potential of an LLM, specificity is key. The more precisely you define a task, the deeper the LLM can dive, producing higher quality and more accurate outputs. Essentially, by narrowing the task's breadth, you channel the LLM's capabilities into depth—its area of expertise. However, while specificity can enhance an LLM's performance, remember what your goal is. Strike a balance: the LLM should amplify your work, not create additional burdens. If prompting the LLM takes more time than the task itself, it defeats the purpose. If augmenting your own workflow, use LLMs to complement, not complicate, your workflow. On the other hand, if you're completely automating workflows using an LLM, then complete, absolutely specificity is the goal.
- Prompt effectively: Provide specific context, instructions, directions, and examples to guide the LLM to the desired result.
- Define the task with precision: The more specific the instructions provided to an LLM, the more effectively it can apply its 'ability' to depth, resulting in higher quality outputs.
- Balance depth and breadth: Narrowing the task's scope allows the LLM to focus on depth, but where appropriate, don't overlook the need for versatility.
- Efficiency is key: The time spent on setting up the LLM should not exceed the time it would take to complete the task manually.
- Full automation requires complete specificity: When automating workflows with an LLM, detailed and comprehensive instructions are essential to achieve the desired outcome.
- Understand the 'ability' threshold: Recognise the maximum 'a' value for each task to gauge the LLM’s potential performance.
- Utilise conservation of 'ability': Adjusting depth and breadth should maintain a constant 'a', similar to conserving energy in a closed system.
- LLMs as force multipliers: Leverage the model to multiply cognitive efforts.
- Chain models to automate complex tasks: Use multiple specialised models in a sequence for tasks that require a range of expertise.
Final Notes
Finally, I'd like to mention that this page is still very much a work-in-progress, and that a lot of these ideas have come about by discussions with my friends and colleagues. I've been writing small sections on the way to work most mornings, but this is still quite broad and disparate. This page is simply an attempt to get it all down in one place. If you see something you agree/disagree with, or would like to see expanded/explained, or really anything at all, please feel free to reach out and send me an email - I'll always be willing to discuss this stuff, and am eagerly hoping for feedback.